clinical genetics
Raw DNA Data Privacy: What Happens After You Upload
Genetic data is the most personal data you have. Here is exactly what GenoSight does with your raw DNA file — encryption, access, what is sent to AI, and deletion.
Sebastian Thorp · May 1, 2026 · 6 min read

In short
Your raw DNA file is the most personal data you have. Before you upload it anywhere, you should know exactly what happens to it. This page covers what GenoSight does with your file — how it's stored (encrypted at rest, access restricted by row-level security), what gets sent to the AI (a small set of structured findings, never the raw file itself), what isn't shared with third parties, and how deletion and portability work. The goal is full transparency: nothing about how we handle your data should be a surprise after you read this.
Why this matters more than for other data
A genetic file is unique in three ways that change how it should be handled.
It's permanent. Your password can be changed; your SSN can be reissued in extreme cases; your DNA cannot. A genetic file leaked today is leaked for the rest of your life.
It's familial. Your DNA contains information about your siblings, parents, children, and more distant relatives — none of whom consented to the upload. Carrier status, ancestry composition, and shared variants all leak family information from a single individual's file.
It's deeply personal. Your file contains markers for traits and conditions you may not know about yourself, including things you might never want to know. Trustworthy handling means leaving you in control of what surfaces and what stays untouched.
Those three properties drive the design choices below.
What GenoSight does with your raw file
For the broader context of what GenoSight is and what the report contains, the privacy story below sits inside that bigger picture: every choice about storage, AI handling, and deletion is made before any of the synthesis described in those posts can run.
Storage
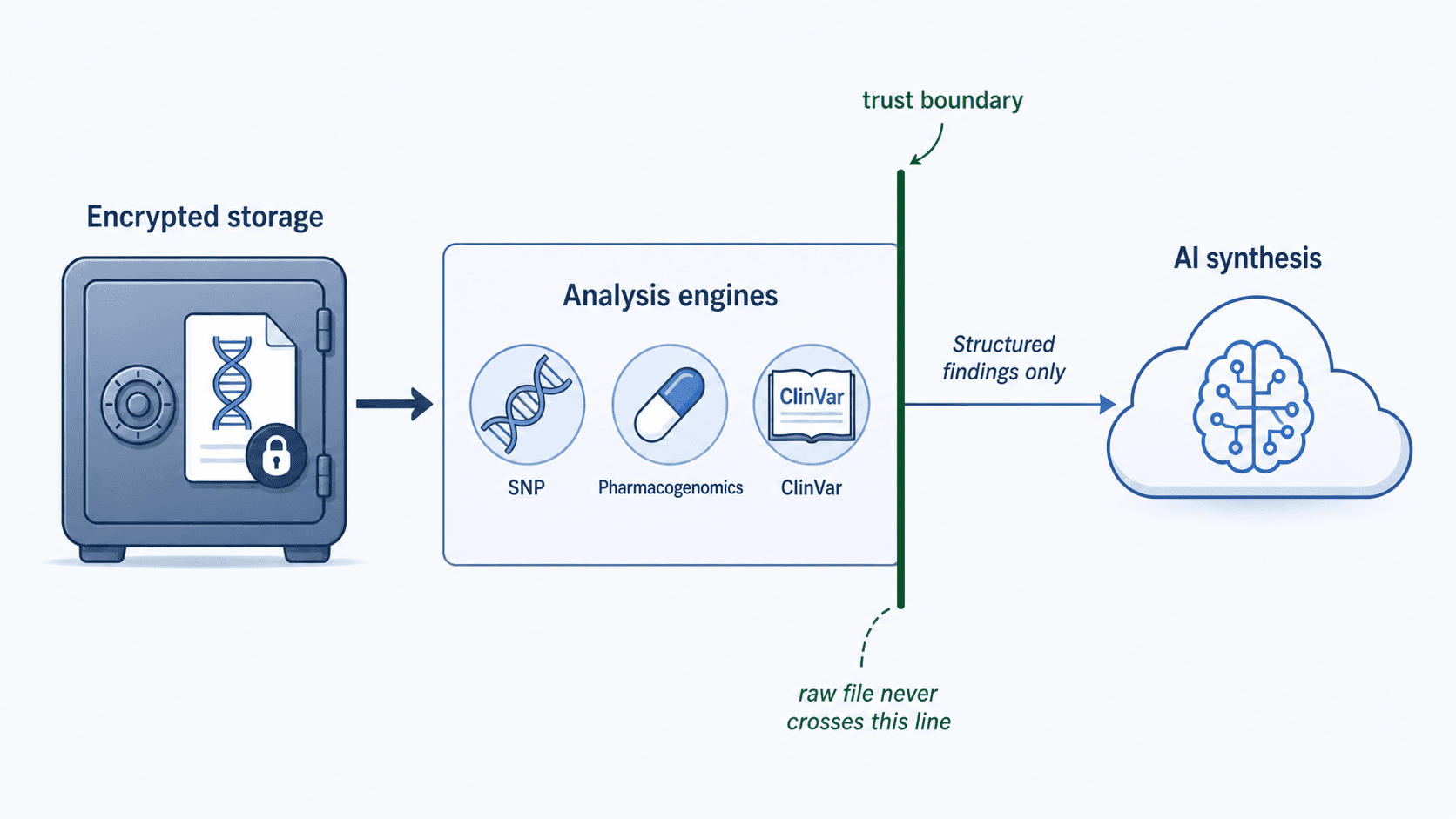
When you upload a raw genotype file, it's stored in encrypted-at-rest object storage. Encryption keys are managed by the storage layer, separate from the application database.
Database access is restricted by row-level security — every query against your data is automatically filtered so that no other user (and no developer running ad-hoc queries) can read your records. This is enforced at the database layer, not in application code, so a bug in the application can't accidentally bypass it.
What gets sent to the AI
This is the question most people care about, so to be precise: your raw genotype file is never sent to the LLM.
When the analysis pipeline runs, the engines (lifestyle SNPs, PharmGKB, ClinVar) read your file from encrypted storage and extract a small set of relevant variant calls — typically a few hundred matches from a file that contains hundreds of thousands of positions. (Walk through the full five-stage pipeline.) Only those structured findings, plus the personal profile you completed during onboarding, are sent to Anthropic Claude for synthesis.
The synthesis prompt looks roughly like: "Given these structured findings (variant + genotype + cited effect) and this user's profile (age, sex, ancestry, current supplement stack, stated symptoms, habits, goals), produce a synthesized educational report." Claude never sees the rsIDs the engines didn't surface, never sees the rest of your file, and never sees raw nucleotide data. Genosight does not collect medical diagnoses, prescription medications, family medical history, or lab values — none of those are in the prompt because none of those are in our database.
The model also operates under a strict constraint: it can only cite findings provided in the prompt. Hallucinated variants would be caught by post-synthesis validators that re-check every claim against the engine outputs.
What isn't shared with third parties
GenoSight doesn't sell genetic data to research partners, pharmaceutical companies, or anyone else. There's no opt-in dropdown that quietly enrolls your file in research databases. The only third-party services your data touches are infrastructure providers (Supabase for database and storage; Anthropic for LLM synthesis) operating under their respective privacy commitments — and even there, only structured findings (not the raw file) cross the boundary to the LLM provider.
If that ever changes, it would happen with explicit prior notification and an opt-in choice — not buried in updated terms.
Deletion
You can delete your account and your data at any time. Deletion removes:
- Your raw genotype file from encrypted storage
- All analysis findings derived from it
- Your health profile
- Your chat history
- Your generated reports
Deletion is full removal, not a "soft delete" flag — within the operational backup retention window (necessary for disaster recovery), the data is purged. Backups follow standard infrastructure retention policies and are also encrypted at rest.
If you want a copy of your data before you delete, the export endpoint returns your raw file, profile, and report contents in a portable format.
What we log (and why)
For operational reasons we log application-level events (a report was generated; a chat message was sent). These logs include identifiers — user ID, report ID — but not raw genotype data and not chat message content beyond minimal metadata needed for billing (credit usage).
Cost-tracking logs record API spend per LLM call. They don't contain prompt or response content.
How this compares to industry norms
Three reference points worth knowing.
23andMe and AncestryDNA offer research opt-in by default at signup (you can opt out). Aggregated, de-identified data is shared with research partners or, in 23andMe's case, has been subject to commercial deals with pharmaceutical partners. Both companies have suffered notable data incidents in the last several years. (How GenoSight compares functionally to other DNA analysis services.)
Smaller analysis tools (Promethease, SelfDecode, others) have varied policies — some store the raw file long-term, some don't. The relevant question is: read the privacy policy and look for explicit answers to "what gets stored, what gets shared with third parties, what gets sent to AI providers."
GenoSight's posture: encrypted storage, no third-party data sales, raw file never sent to LLMs, deletion fully removes data within standard backup retention windows. That's the design intent and the operational practice.
Practical recommendations before any genetic upload
Three habits worth adopting regardless of which service you use:
- Read the privacy policy specifically for "research opt-in" and "third-party sharing." If it's opt-in by default and you didn't catch the toggle, change it.
- Use a unique strong password and 2FA. Account takeover is the most likely compromise vector.
- Decide what you don't want to know. Some services (and GenoSight) let you scope what gets surfaced. If there are conditions you don't want included in your report, configure that during onboarding.
If you want to evaluate GenoSight before uploading, start with the raw DNA file checker, compare the free raw DNA analysis trial, review pricing and free credits, or read the raw DNA analysis cost guide.
Try GenoSight free
Encrypted storage. No third-party data sales. Raw file never sent to the LLM. 250 credits to start.
If the privacy model works for you and you want more than the trial credits, choose monthly for 1,500 monthly credits, PDF exports, regenerations, and findings-grounded chat.
Key takeaways
- Genetic data is permanent, familial, and deeply personal — handling decisions matter more here than for most other data types.
- GenoSight stores your raw file encrypted at rest with row-level security restricting access to your account only.
- Your raw genotype file is never sent to the LLM — only structured engine findings (variant + genotype + cited effect) and your personal profile go to Anthropic Claude for synthesis.
- No third-party data sales. Infrastructure providers (Supabase, Anthropic) operate under their own privacy commitments; only structured findings cross the LLM boundary.
- Deletion fully removes your data within standard backup retention windows. Export is available before deletion.
Sources
- 23andMe data leak — comprehensive incident overview — https://en.wikipedia.org/wiki/23andMe_data_leak
- PostgreSQL — Row Security Policies documentation — https://www.postgresql.org/docs/current/ddl-rowsecurity.html
- NIST FIPS 140-3 — Cryptographic module validation standards — https://csrc.nist.gov/projects/cryptographic-module-validation-program
- Anthropic — commercial terms and data-handling policies — https://www.anthropic.com/legal/commercial-terms